3 min de leitura
Criando um "chatGPT" em sua máquina local
Por que utilizar um “ChatGPT” local?
- Privacidade: Leia os termos de uso e políticas de privacidade das soluções famosas disponíveis. Não é segredo que podem utilizar seus para treinamento da “IA”. Se for utilizar com dados sensíveis o melhor caminho é ter seu chat local.
“Se você não paga pelo produto, você é o produto.”
-
Contenção de custos: Se você realiza um alto volume de execuções, como um script que utiliza alguma LLM para funcionar, tem ciência (ou deveria ter) que essa brincadeira pode doer no bolso. Talvez, seja um excelente aliado ter seu modelo rodando localmente lhe economize um bom dinheiro.
-
Indisponibilidade: por não depender de conexão com a internet, indisponibilidades seja da operadora e/ou da solução não afetarão a sua execução. O chatGPT, por exemplo, já ficou indisponível por algumas vezes.
O que será necessário
Para executar modelos de IA localmente em sua máquina, com o mínimo de performance, você precisará de:
- Computador (óbvio!), sendo:
Ideal: com placa de vídeo offboard NVIDIA com no mínimo 12gb de VRAM Nota: NVIDIA por conta dos núcleos CUDA (assunto para um próximo post)
Básico: com processador Ryzen série 5 + 32gb de RAM
-
Ollama: ferramenta de código aberto que facilita e permite a execução de modelos de LLMs em computador local
-
Terminal: CMD (Windows), Terminal (Linux), etc.
OFF TOPIC:
O cálculo de VRAM e RAM necessárias para rodar modelos de IA depende de alguns fatores como tamanho do modelo, formato do modelo, tamanho do batch e estratégia de offloading. Não vamos aprofundar nos conceitos neste momento, porém, para fins de testes, sugiro a seguinte métrica:
Número de parâmetros =< quantidade de VRAM
Exemplos:
- 4GB VRAM → Modelos pequenos (1B~3B)
- 8GB VRAM → Modelos médios (7B)
Veja a tabela abaixo, considerando modelos LLaMA:
| Modelo | Parâmetros | FP32 (VRAM) | FP16 (VRAM) | INT8 (VRAM) |
|---|---|---|---|---|
| LLaMA 7B | 7 bilhões | ~28GB | ~14GB | ~7GB |
| LLaMA 13B | 13 bilhões | ~52GB | ~26GB | ~13GB |
| LLaMA 30B | 30 bilhões | ~120GB | ~60GB | ~30GB |
| LLaMA 65B | 65 bilhões | ~260GB | ~130GB | ~65GB |
Passo-a-passo
1. Acesse ollama.com e clique em “Download”;
2. Baixe a versão para o seu sistema operacional. Aqui utilizaremos o Windows (sim, o Windows!);
3. Prossiga com a instalação;
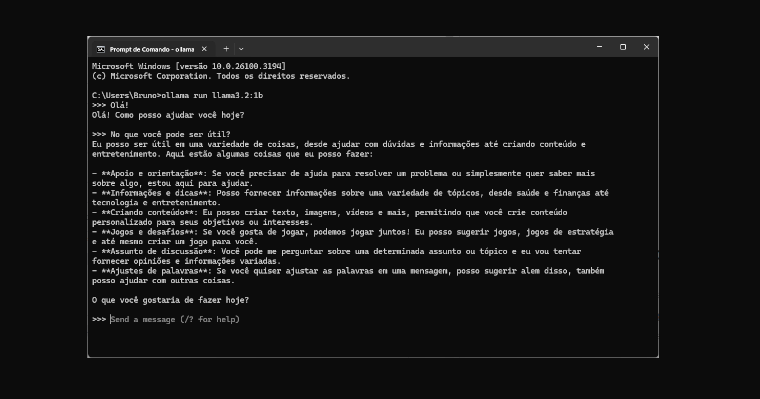
4. Volte para ollama.com, clique em “Models” no menu e escolha um modelo. Minha sugestão é começar com o llama3.2 (3b) ou, o tão falado do momento, deepseek-r1 (1.5b)
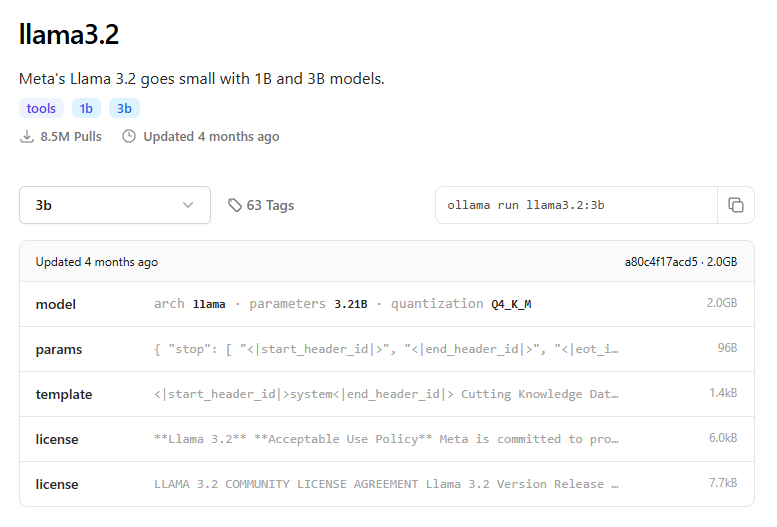
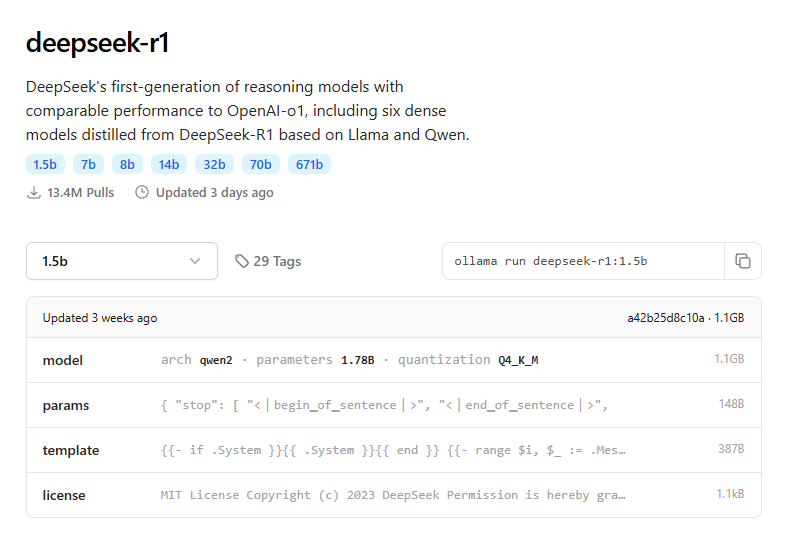
5. Selecione o tamanho do modelo (no exemplo utilizarei o deepseek-r1 1.5b) e copie o comando para instalação
ollama run deepseek-r1:1.5b

6. Agora, abra o terminal. No caso do Windows abra o CMD;
a. Windows + R
b. Digite “CMD” e dê Enter
Nota: Talvez seja necessário executar o CMD com privilégios elevados. Nesse caso, basta pesquisar CMD no Menu Iniciar, clicar com o botão direito do mouse e selecionar “Executar como administrador”
7. No CMD, cole o comando copiado no passo 5 e dê Enter
8. Após a finalização, já estará apto para utilizar o seu chat com IA particular.
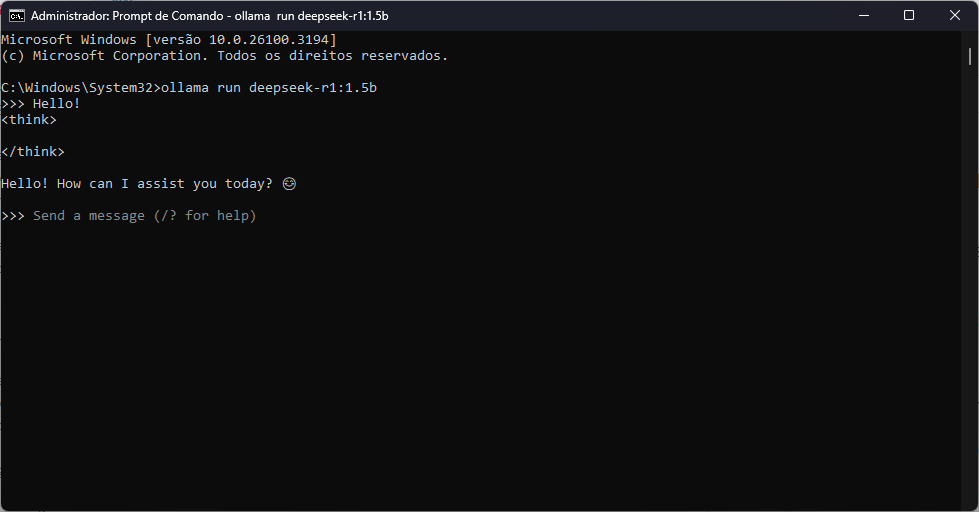
Isso é só o começo e as possibilidades podem se expandir bastante. Você pode melhorar a interface com um design mais intuitivo, integrar comandos de voz para uma experiência mais interativa, armazenar históricos de conversa para referência futura e até conectar a IA com APIs externas para automação de tarefas (nesse caso, porém, lembre-se do ponto privacidade!). Além disso, otimizações como ajuste do modelo utilizado, personalização de respostas e integração com bancos de dados tornam o seu chat pessoal ainda mais poderoso e adaptado às suas necessidades.


Comentários